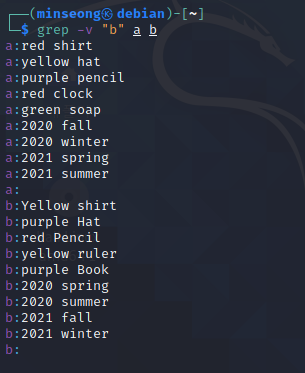
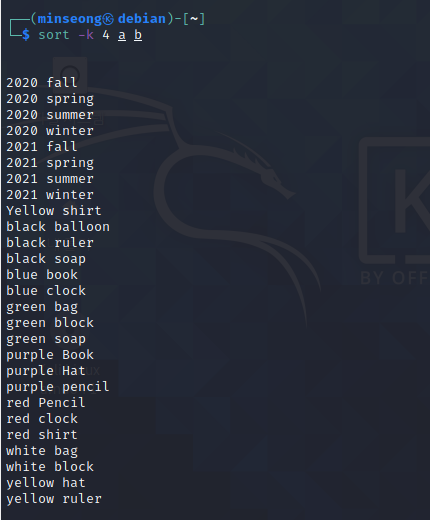
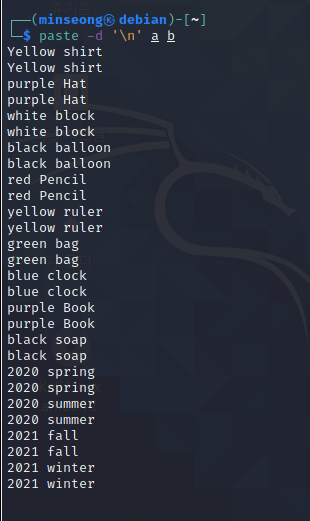
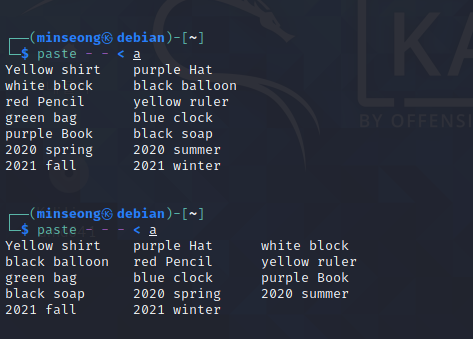
[ 과제1 ]
3주차 내용 문서화
- 포인터
- 포인터와 참조의 차이
- 함수의 인자 전달방식(call by value, call by address, call by reference)
1. 포인터
포인터란 어떠한 값을 저장하는 게 아닌 메모리 주소를 저장하는 변수이다.
& : 주소 연산자
* : 역참조 연산자 (포인터가 가리키는 메모리 안의 값)
1-1) 포인터 선언 및 초기화
포인터 변수가 가지고 있는 주소를 가리키는 '변수'의 데이터를 읽을 때, 자료형에 따라 읽는 바이트의 량이 달라진다.
int 형은 4byte, char 형은 1byte, double 형은 8byte 만큼 읽는다.
추가적으로 char은 문자 1개를 의미하고(예시: a, b, i 등), string은 문자를 의미하는 것으로 자료형의 크기는 기본 28byte 이다. (예시: total, result etc)
즉 'int 포인터'는 'int형에 대한 포인터'를 의미한다.
다시 말해 포인터 변수의 자료형은 가리키는 변수의 자료형과 같아야한다.
포인트를 사용시 일반 변수와 마찬가지로 선언 시 초기화가 되지 않으므로, 초기화 되지 않은 값은 쓰레기 값이다.
그러므로 포인터를 NULL로 초기화 해주는 것이 좋다.
1-2) 포인터 연산
포인터 = &변수
int p = 25 (주소값 : 0073FB2C) 라 할 때
int *ptr = &p
-> ptr은 값으로 p의 변수 값의 주소를 가지고 있다. 즉 ptr은 007FB2C 값을 갖고 있는 것이라 할 수 있다.
1-3) 포인터 변수의 크기
일반적으로 포인트 변수의 크기는 32비트(4바이트)로 동일하다.
int형이 4 바이트, char형이 1바이트, doubld형이 8바이트이다.
1-4) 포인터의 필요성
번거로운 포인터의 사용하는 이유는 무엇일까?
1. 배열은 포인터를 사용하여 구현되기 때문에, 포인터는 배열을 반복할 때 사용할 수 있다. c++에서 동적으로 메모리를 할당할 수 있는 유일한 방법이다.
2. 데이터를 복사하지 않고도 많은 양의 데이터를 함수에 전달할 수 있다.
3. 데이터를 복사의 방식이 아닌 많은 양의 데이터를 함수에 전달할 수 있다.
4. 함수를 매개 변수로 다른 함수에 전달하는 데 사용할 수 있다.
2. 포인터와 참조의 차이점
2-1) 참조(레퍼런스)의 개념
참조는 자신이 참조하는 변수를 대신할 수 있는 또 하나의 이름으로 별명같은 것이다.
참조는 &을 이용하여 선언을 하게 되는데,
이미 선언된 변수의 앞에 & 연산자가 오면 주소 값의 반환을 명령하는 뜻이지만,
새로 선언되는 변수의 이름 앞에 오면 참조의 선언을 뜻하게 된다.
2-2) 포인터와 참조(레퍼런스)의 차이
차이점을 알아보기 전에 포인터와 참조의 공통점은 무엇일까? 바로 모두 대상을 가리킬 때 사용하는 변수타입이다.
그렇다면 포인터와 참조(레퍼런스)의 차이점은 무엇일까?
가장 크게 나타나는 두 가지 차이점은
첫 번째, Null의 허용 여부로 포인터는 Null 값을 허용하지만, 참조는 Null 값이 될 수 없다. 즉 Null 값이 없다.
여기서 Null 값이란, 결정되지 않거나 모르는 값을 의미하는 데, 참조는 선언과 동시에 초기화를 해야 하기 때문에 Null값이 없다.
두 번째, 참조 대상 할당 및 접근의 차이점으로 참조자는 변수를 입력 받고, 포인터는 주소값을 입력 받는다.
그리고 참조자는 한번 지정한 객체를 변경할 수 없지만, 포인터의 경우 주소값을 변경하는 경우 객체를 변경할 수 있다.
3. 함수의 인자 전달 방식
3-1) call by value
: 값에 의한 전달
함수 호출 측(주로 main)의 실 매개변수는 함수 측(형식 매개 변수)으로 값만 전달하는 것으로 함수로 값을 전달하면 그 값이 함수의 매개변수에 복사가 되며 함수 내에서 값을 아무리 바꿔도 원본의 값은 바뀌지 않게 된다.
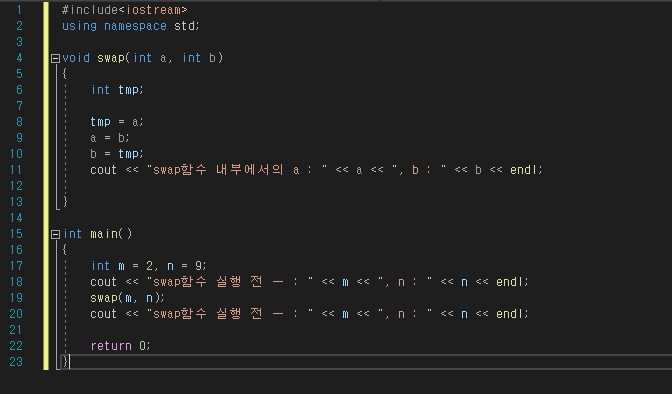
위의 코드를 쳤을 때,
아래와 같은 실행화면이 나온다.
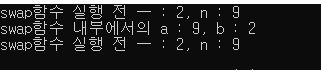
3-2) call by address
: 주소에 의한 전달
우선 함수에 매개변수로 포인터형 변수를 선언하고, 그 포인터 변수의 공간에 원본의 주소값을 복사하게 된다,
그 후 주소를 참조하여 가르키는 곳의 값을 변경하게 되면 원본의 데이터가 수정이 된다.

위의 코드를 쳤을 때,
아래와 같은 실행화면이 나온다.

3-3) call by reference
: 참조에 의한 전달
call by reference라는 rjtdms c에는 애초제 없고, c++에서 등장한 참조의 개념이다.
함수가 호출이 되는 시기에 매개변수인 참조 변수가 받앙오는 변수의 별명으로서 초기화가 이루어 진다.
즉 참조 변수는 메모리 공간을 따로 할당 받는 것이 아닌 원본 변수의 별명으로써 존재하게 된다.
참조 변수는 그 변수 자체를 참조하여 값을 변경할 수 있기 때문에 함수 내에서 값을 변경해도 원본 변수의 값 또한 바뀌게 되는 성질을 가지고 있다.

위의 코드를 쳤을 때,
아래와 같은 실행화면이 나온다.

[ 과제2 ]
'Language > C언어' 카테고리의 다른 글
| [ c++ week4 ] 과제1,2 (0) | 2021.05.16 |
|---|---|
| [ c++ ] 재제출 영화 선택 과제 (0) | 2021.05.10 |
| [ C++ week3 ] 과제2 재제출 (0) | 2021.05.08 |
| [ c++ ] cstring 함수 재제출 (0) | 2021.04.03 |
| [c++] string class 함수 (0) | 2021.03.30 |